
Hunspell
What it is
You might have heard about hunspell, a spell checker used by software like OpenOffice, LibreOffice and Mozilla products just to list a few of them. It’s often a built-in feature packaged with the software, allowing users to install specific dictionaries for their needs so the text that they input can be checked for mistake. It’s really useful for communities because anyone can join and add their contribution to the work, and data are stored in a simple and really accessible way.
The data
To be a little more concise, a dictionary is a bundle of 2 files :
- One large “.dict” file with the list of every word plus a few extra information (noun or verb? gender? etc…) – except the definition itself
- Another “.aff” file with the specific language’s rules like grammar – tiny just the strict minimum
Data are saved as separated plain text, no need to decompress or do whatever action, it can be a big heavy in size but you can open and edit it with a simple text editor like NotePad++ ! Pretty cool, isn’t it ?
The end?
Everything sounds great but actually it’s a big deal for developers like me working with browsers – the software you are using to display content on the web like Mozilla Firefox, Google Chrome, or Microsoft Edge . Even the feature is enabled and sometimes built-in and ready to use, and even if some dictionaries are already available as different formats inside your operating system – the environment used to run your software like Linux, Apple MacOS or Microsoft Windows, the program running the editor inside your browser for you to edit your content – also known as WYSIWYG (What you see is what you get) – can’t access those data. Or at least not in a easy and universal way.
It might not sound logic, but it is. Really. You wouldn’t speak to yourself alone in front of your desk the same way you speak to a person sitting next to you, would you? Web content management systems are lines of code running inside your browser – so on your local computer – but using components and data from remote locations like your web hosting. As soon as networking is involved, everything is different, permissions granted are not the same, and next…
Semantic glitch
As soon as we are dealing with multiple languages or multiple timezone for example, there are always different approaches to solve a problem. In my case I do as usual: look what was already done! Or start to look by what is already available on the market! (Same mind, just different words ^^).
The lite / free version of Markup Markdown is based on EasyMDE , an open-source editor to work with Markdown that uses CodeMirror as its core engine. To give an image CodeMirror is for EasyMDE what the motor is for your car or your bike.
On Github there are several updates that were already made. Looking at the following pull-requests :
- https://github.com/Ionaru/easy-markdown-editor/issues/78
- https://github.com/Ionaru/easy-markdown-editor/pull/333
It was unexpectedly great! And not completely what I was looking for. Give me a few minutes of your time to explain: loading a dictionary in a different language is something related but different. It’s called :
Internationalization
The process to make a software available in another language is called internationalization, part of a bigger process / group to create content in a different language called “translation”. You add extra data like translations files and features if need be like the possibility to write text from right to left as an example so users speaking a different language can fully use your software. And by different language this does not mean a different country! In Switzerland there are German, French and Italian variants. And if you add the country’s local languages like the Breton in France, well… it’s getting tough! :D
English being the international language by default, if your software was not designed for a specific country, you often start with English language as default – or your native one – and then later release what we called “language packs”. For example I used to work with an English Edition of MacOS with additional Asian languages (Japanese, Chinese, and Corean). Or the French Version of Microsoft Word inside an English Edition of Windows. Those are related to internationalization: You mostly run one specific language at a time so basically you need different data languages at specific frames like having an English dictionary to check a word you wouldn’t know.
Multi-language
Or Multilanguage, multilingual, … and any derivative word is the support to work with different languages on your environment. You have to give power to the users for them to use several languages within your software. It’s not complex, but far from being easy as well. Depending on what you are trying to achieve, it can be using different languages at the same time in the same space – for example the spell checking on a document using multiple languages like a Spanish quote in a French text – or in different spaces – for example use the same software to edit the same document in two different languages in two separate windows. It’s becoming really intense!
To follow the previous example, at a more advanced level then inside your OS despite installing language packs, to write in different languages you would need to install a tiny software so you can switch the way you input the word, for example Microsoft IME the “Input Method Editors”. This is multilingual stuff. For you to write a quote in a different language in your blog post, you need the data from other languages to be available as well at the same time. Or in the real life it could be a bilingual French-English dictionary so as a french person I can read an explanation in French language as well while looking for the word in English.
Quick summary
Both are related but regards to user interface, it’s really a different world! If you stick to latin based languages, internationalization is like duplicating and replacing content with a new version. User can display and write content in a specific language, one at a time. I’m not saying it’s easy, it’s already a HUGE amount of work. If you push further, then you move to bilingual or trilingual when the user should have a way to display and write multiple languages at the same time! If you only consider that the display and input hardwares are different – which is the case by the way – then even if it’s not making sense statistically there would be 4 ways to achieve it.
Solution
Back to our markdown editor, CodeMirror has already a SpellCheker plugin, for example this fork, using Typo.js as its core engine which is using Hunspell files! That’s the point. As described in the following issue: https://github.com/cfinke/Typo.js/issues/37
There are actually two patterns :
- Create your own dictionary (bilingual, slang, custom, etc…)
- Load multiple dictionaries
I decided to go for solution 2, loading multiple dictionaries. There are caveats as when using delimiters a piece of word could be identified in different dictionaries… So I made an hybrid solution:
- You install the dictionaries on your web hosting
- Then you define one as the primary language
- Finally when writing your content, you need to flag the piece of text with the alternative language thanks to a specific button in the toolbar
1. Install dictionaries
From the menu Settings -> Markup Markdown, there is now a tab called “Spell Checker (Experimental)”.
Select the target dictionary in the list and click the “Install” link. Let’s proceed with the English dictionary :
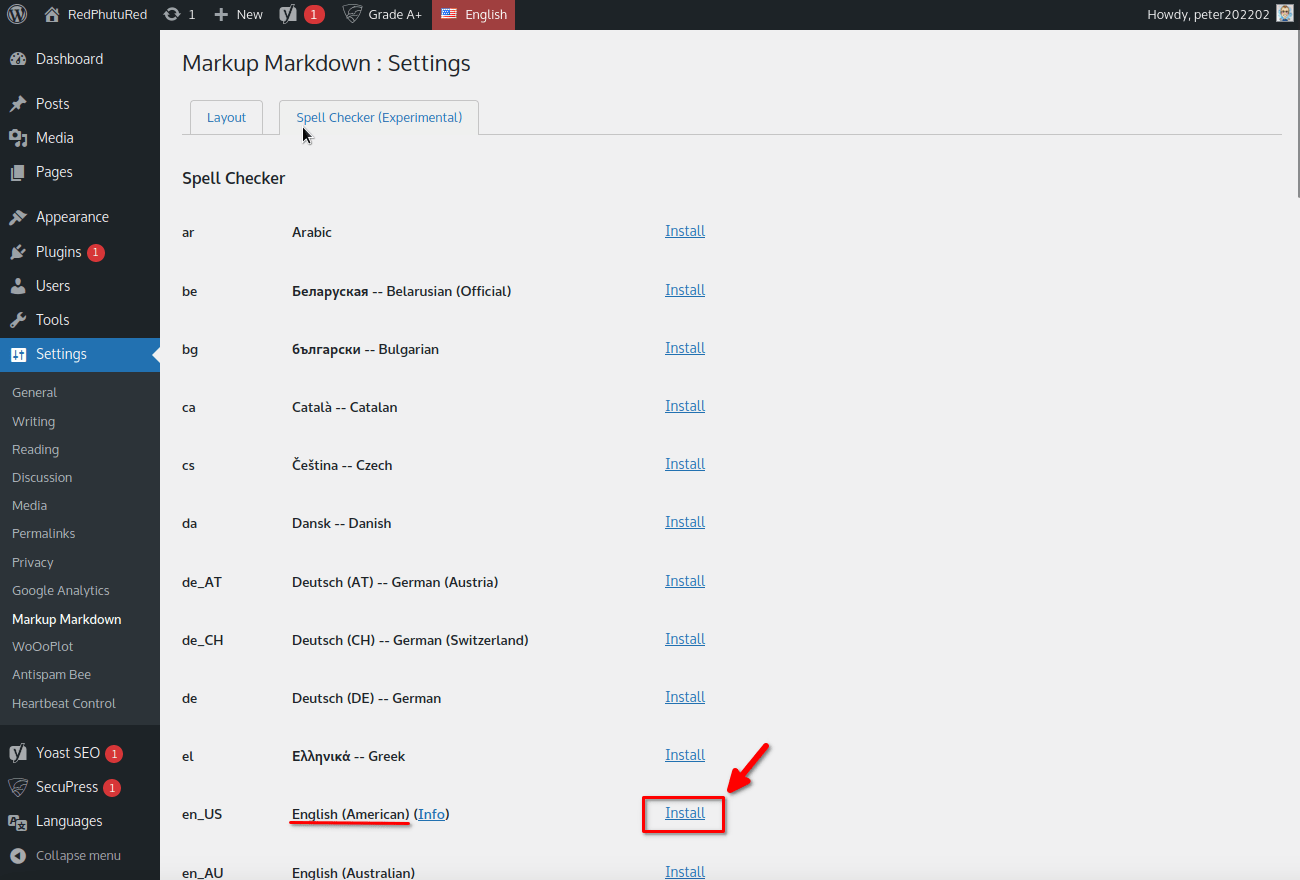
At this point the dictionary data should be downloaded and ready to use. Check the box to set the dictionary as active, and don’t forget to scroll down to the bottom of the page and press “Update” to save your changes.
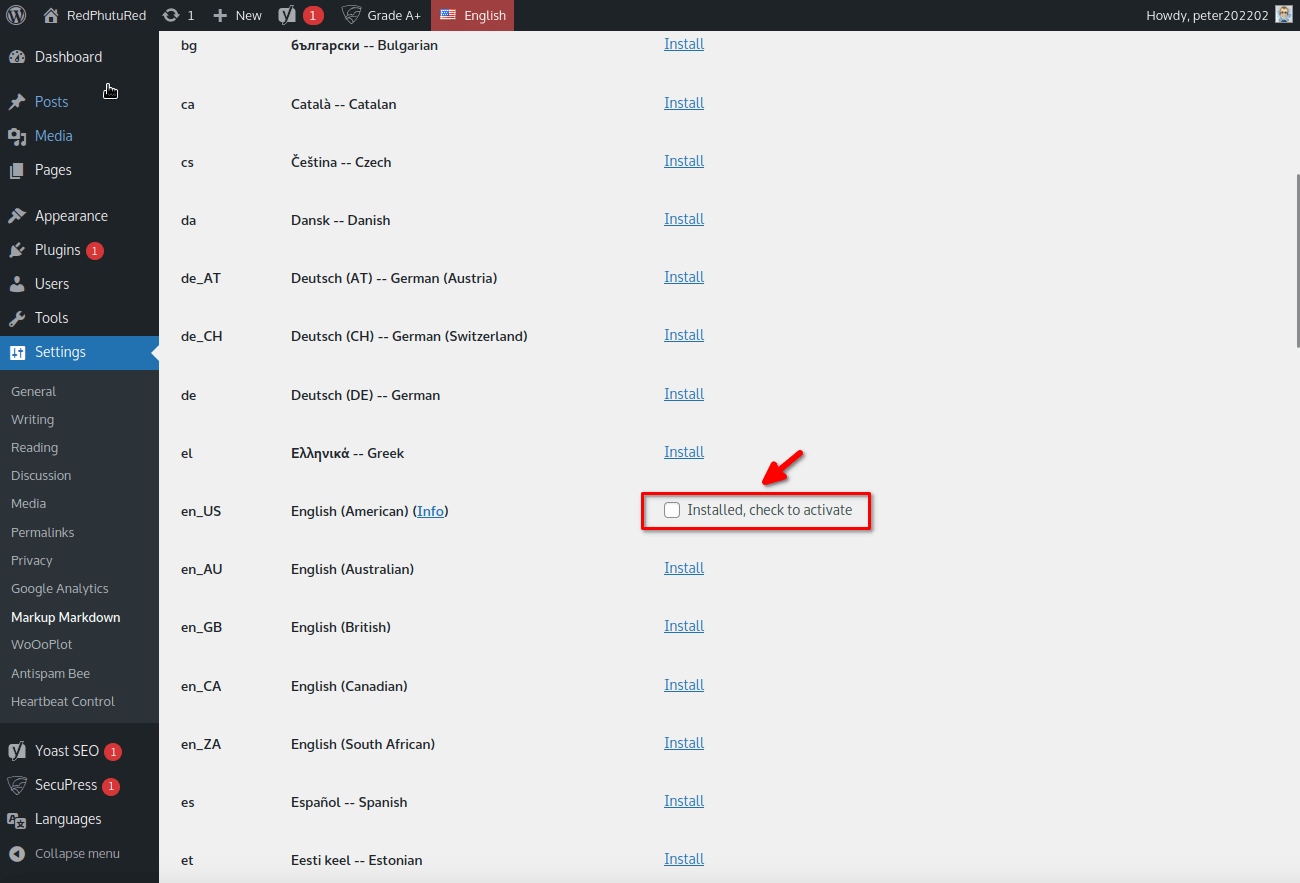
If everything’s fine now the screen should look like this :
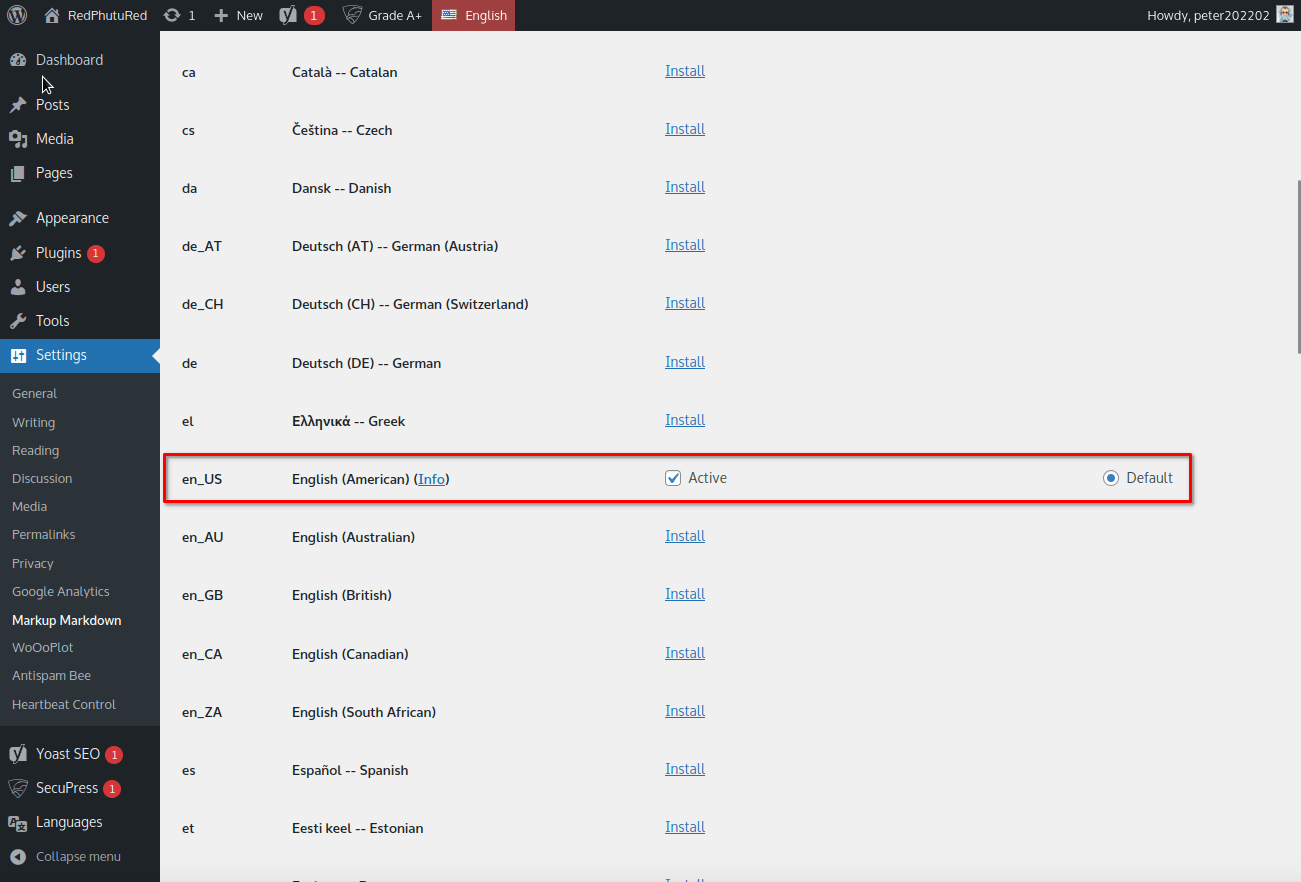
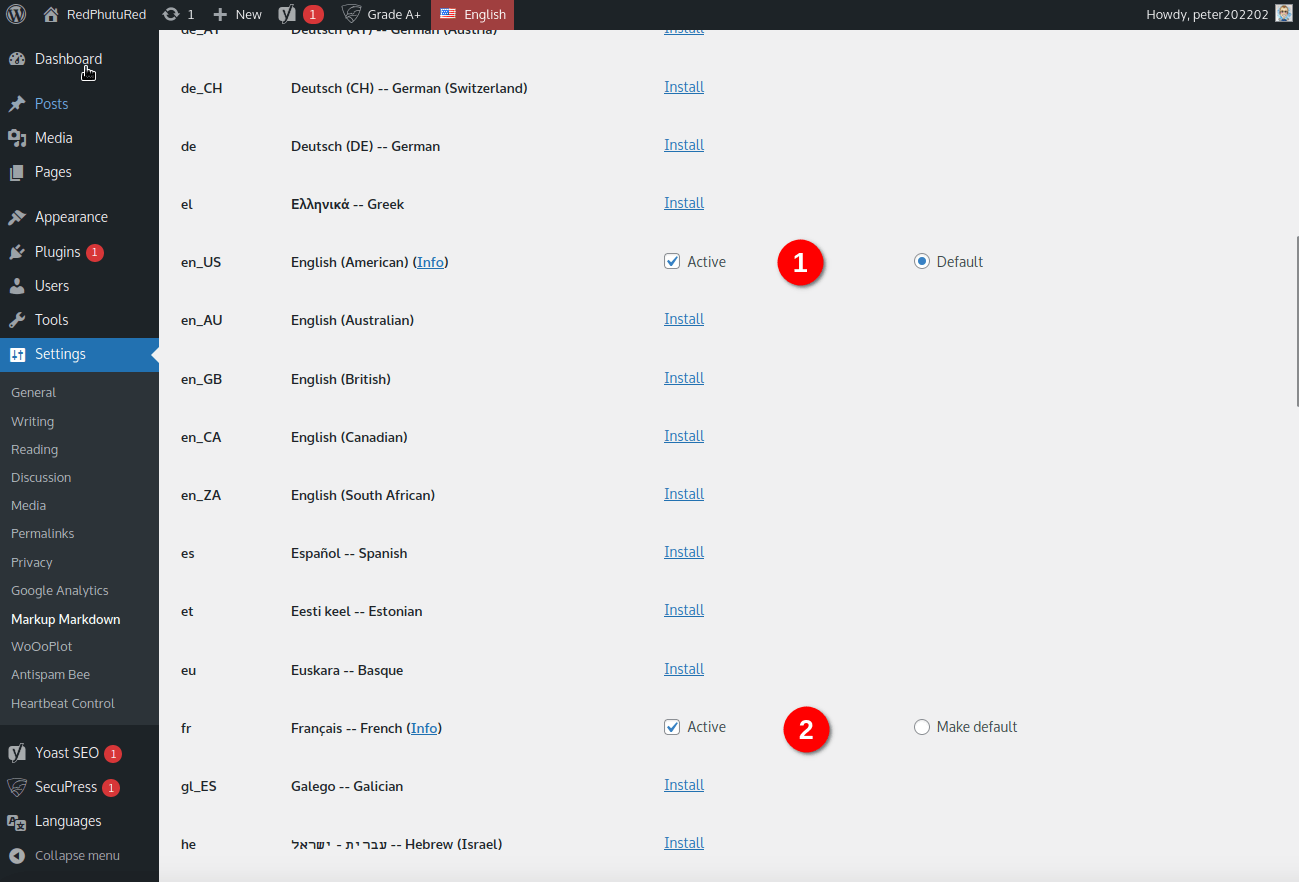
Now let’s do it with the French dictionary. Now 2 dictionaries are now active:
2. Define the primary dictionary
Looking at the previous screenshot, the “active” status is defined by the checked box. If you don’t is now available check it, the spell checking will be turned off for the specific language. Even if you installed multiple dictionaries, you can easily disable or enable it on demand. This feature was useful to me for testing different variants of the same language.
Now on the right side, there is a radio button to set only one dictionary as default: this will be your primary dictionary! What does it mean? In my previous example if I install the English dictionary and then the French dictionary, by order the English is the default one.
So when editing my content, any word will be spell checked with the English dictionary and I would have to flag specific section containing French words. If I set the French as the default one, any word will be spell checked with the French dictionary and I would have to flag specific section containing English words. (Read the next step too)
3. Flag content with alternative language
This is the final and most interested part. Following my previous example here is a screenshot of the editor with the English dictionary set as default and the French language as an alternative language. Inside the toolbar you can notice between the headlines and the quote button, a new button “FR” (code for the French language) is now available.
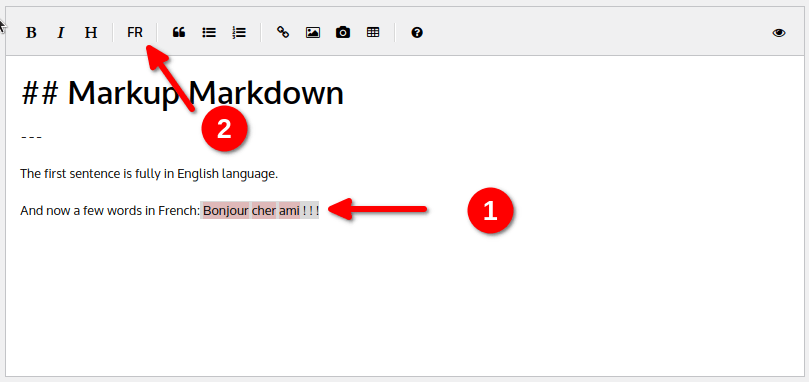
English being the default language, every french word – “Bonjour cher ami” which means “Hello my friend” by the way – is marked as an an error… So let’s fix it!
Select the text (Grey color in the screenshot) and then press the “FR” button:
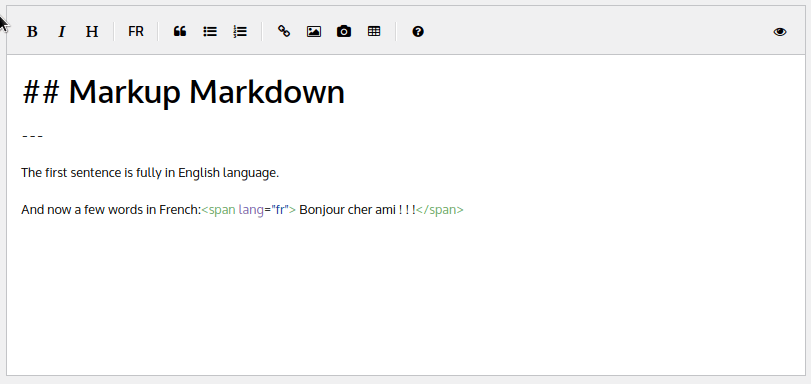
The text is now surrounded by aspan html tag and the language attribute like this:
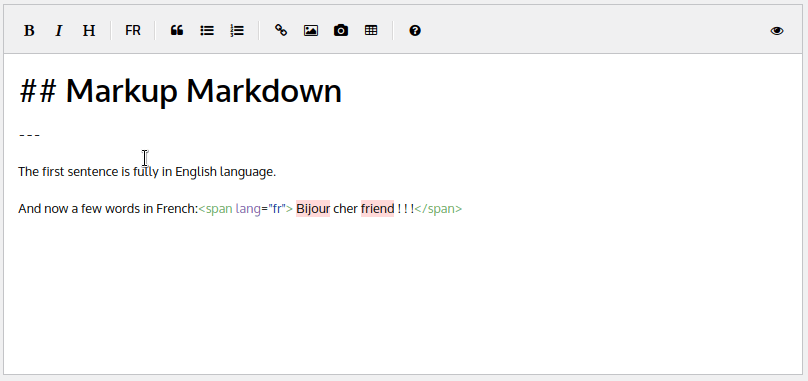
If you try to replace “Bonjour” by “Bijour” -a french slang word- or “ami” by “friend” -an English word- both will be flagged as error :
If you didn’t know actually regards to accessibility specifications you are supposed to set in the html code the alternative specific language section, so make the setup manually won’t hurt anybody at all! ;-)
Final words
Please remember dictionaries will be loaded through the browser’s memory and can be heavy in size so try with 1 or 2 dictionaries first. A few disclaimers and details are written in the setup screen so please read them to find out more.
There might be other solutions like enabling native spell checking but as far as I researched and tested, setting manually the specific content with the appropriate flag was the best accurate way to do it!
Lots of ideas in my head pop up now, it was challenging and it’s just a beginning, I’m really glad I got something working and hope the feature will be useful AND usable to more people as well.